Automated transcription has improved greatly since the release of OpenAI Whisper. Many software programs are using base Whisper models, and others are creating their own models on top of the base model to further improve accuracy. We can setup our own workflow to do automatic transcription free! (if computing cost is not counted)
Automated Transcription
Automated transcription is a process whereby machines convert spoken language in audio or video recordings into written text. This technology, often referred to as Automatic Speech Recognition (ASR) or Speech-to-Text (STT), relies on complex machine learning models and neural networks. These systems are trained on vast datasets, comprising millions of hours of audio and corresponding text transcripts, to learn to transcribe spoken words accurately. Popular ASR platforms and automatic transcription tools include Amazon Transcribe, Google Speech-to-Text, Azure Speech, Zoom Automatic Transcription and Whisper.
Challenges Running Whisper On Your PC
Unless your PC has a good graphic card with memory >= 8 GB, running Whisper will be a pain. Even with a good graphic card, transcribing an hour of audio/video will take approximately an hour. This also requires your PC not to go into idle mode and be active when transcription is processing; otherwise, the process will stop. So what is the solution? Cloud is the way to go. You can spin up resources on AWS, Google Cloud, Digital Ocean or Azure anytime and terminate them when not needed. For this one, we will use AWS EC2 & S3.
Setting Up AWS EC2
AWS, or Amazon Web Services, is a cloud service provided by Amazon. EC2 (Elastic Cloud Compute) is one of their host of services. S3 is a Simple Storage Service where you can store your files (we will upload our audio/video here). Fargate is an alternative for serverless computing, but we have more control by setting up workflow directly with EC2.
Navigate to the EC2 dashboard and spin up an EC2 instance with the following configuration (you can go for a lower or higher one depending on your choice).
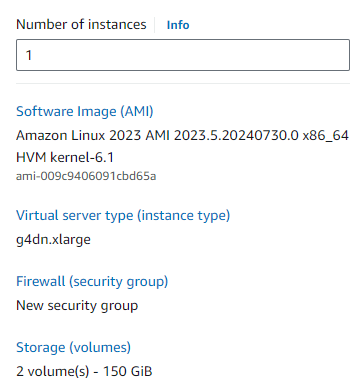
Note: Select the “Deep Learning Nvidia Driver PyTorch” AMI so you don’t have to go into the Nvidia CUDA installation.
Whisper Installation
After you have SSH on the server, start installing Whisper.
Transcription Script
We will now create a script (.py file) that will take argument input as an S3 object path, transcribe it and send the output over email (or Slack, Telegram, or Teams channel).
Example -
Notice the file extension mp4. The user can upload various file extensions, we want to ensure consistency, and we know only audio is processed, not the video. We will convert all inputs we get to the .wav extension using FFmpeg. Use this guide to understand how FFmpeg can be installed - https://www.maskaravivek.com/post/how-to-install-ffmpeg-on-ec2-running-amazon-linux/
At this point, you can do more processing on the audio. At flowres, we have proprietary setups where we process audio to improve transcription output quality. One such process is removing silences from the audio and then adding them back.
If you have English only audios, you can use small model which works fine and will give you output much more faster than the large model.
Test your script by uploading an audio file in your S3 bucket uploads folder (the name can be anything; replace it below accordingly).
Creating AMI
G4dn.xlarge is about $1/hour. If you prefer to keep it running all the time, you will be paying $720 a month - whether you run a single video for a transcript or a few hundred - you will be paying for each hour the instance has been running.
There is also another disadvantage of doing this. If you have two video files of one hour each, and an hour file takes approximately 15 minutes to complete, then you will spend 30 minutes to complete both files on the same instance because you can’t run parallelly. And what if there are 10 files in total? 150 minutes, or 2.5 hours!
To make this work parallelly while paying only for the time the transcription process runs and not the instance, we will create an AMI that can be used to automatically spin an instance for the uploaded file, send it to email (or your channel) and shut down the instance when done. This way, for your 10 files, 10 instances will start simultaneously, and they will consume 15 minutes each to process; you will be charged for 2.5 hours in total while getting all the files in just 15 minutes.
Create Amazon Machine Image (AMI) for the instance where we created our Whisper script by clicking Actions -> Image and Templates -> Create Image.
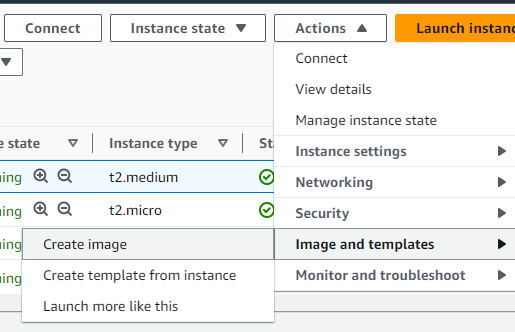
Now, we have an AMI setup that can be launched at any time, and you will not have to set up the instance! Your Whisper script and everything will be there by default.
Automation Script
We need to have connectivity between S3 and EC2. When a file is uploaded on S3, AMI is automatically used to launch an EC2 instance, and a script runs. This means there has to be a server in between that does this. Creating another EC2 that does this short-lived script is not a good option. We will go serverless for this! Using the AWS Lambda service, we will create a trigger that runs a script on Lambda every time there is an upload on S3.
But first, we need to create a page where users can upload files directly to the “uploads” folder.
Start by creating an uploading page that uploads audio/video on AWS S3 using AWS SDK (https://docs.aws.amazon.com/AWSJavaScriptSDK/v3/latest/client/s3/)
Navigate to the Lambda dashboard and create a function. You can name it “spin_transcription_ec2_on_upload.” Select the runtime of your choice and create the function.
In the function overview, click the Add trigger option and select S3 as the source.
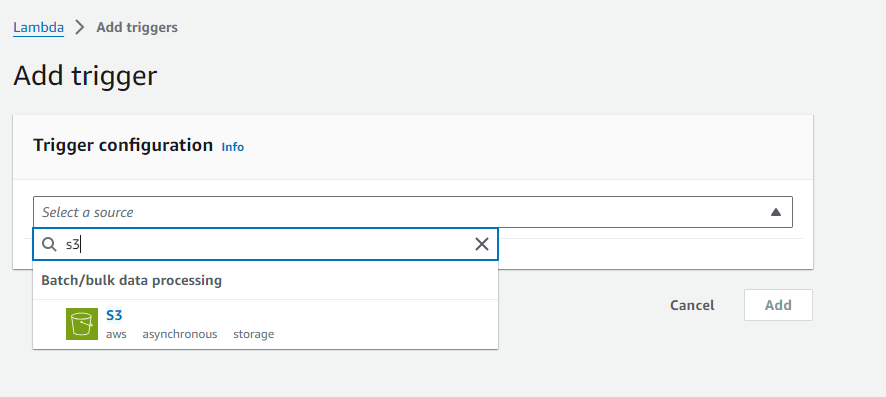
Fill in the required details. In our case, the prefix will be “uploads/”.
Now, your Lambda function will run every time an object is created (uploaded) in the “uploads” folder.
But what does the function do? Nothing! Because we haven’t written anything.
Here is an idea of what your function should do, which you can implement in your preferred runtime.
Get the S3 path from the lambda event, spin the EC2 instance, and pass the ip_adress to the execution function with S3_path. The rest of the process your Whisper script will handle.
What’s Next
We have covered the base installation and automation. Ideally, you should terminate the instance instead of shutting it down. For the same, you can pass instance ID to the instance and use EC2 terminate_instances API to delete the instance.
You can also add speaker diarization using Pyannote, converters to get output in the specified format, and, of course, connect to your Microsoft Teams, Slack or Telegram channel to get real-time notifications of files.
Once your base setup is complete, incrementally updating the script per your organization's needs is straightforward. I have created a repository on GitHub for my Whisper script, so when I want to make any update in the automation flow, I just push my update on GitHub and have added execution of the “git pull” step in the Lambda function. I did not add these details to this blog for the sake of simplicity, so base installation can be done without moving from one library and tool to another.
If you want to move beyond automated transcripts and step into analysis, ask queries on multiple transcripts, do check out flowres.io! flowres is an online qual platform with capabilities including meeting assistant, backroom live streaming, auto transcription, transcription editor and flowresAI chat + grid.

Kawalpreet Juneja
(Tech Head @ flowres)
I love creating lovable products ♥
Posted on: Aug 05, 2024

